If you want to know the kinds of activities and innovation happening at the intersection of culture, academia, and AI, you can find it in the presentations at Fantastic Futures, the international conference on AI for Libraries, Archives, and Museums (AI4LAM).
Fantastic Futures 2024 (FF2024) took place on October 15-18, 2024 at the National Film and Sound Archive of Australia (NFSA) in Canberra, Australia. It was an honor to be able to present my work on AI in the education sector, to meet lots of new people from around the world, and to learn about how people are adjusting to the emergence of Generative AI. As I always do at conferences, I took notes of things that were novel, interesting, or relevant to my work and have compiled them here along with photos. The sessions were recorded and are available on the conference website.
Themes included:
- AI tools and techniques can rapidly accelerate projects and previously time-consuming tasks, but it is worthwhile to test different models for varying accuracy rates and appropriateness to the project requirements
- AI transcription and voice recognition software can be problematic, but models are still useful for speeding up digitization and increasing access to collections
- Now at the point in AI / Generative AI development where researchers and cultural heritage professionals need evaluation frameworks for AI tools
- Indigenous data sovereignty and working with communities and artists/creatives openly are important, and finding ways to give people agency and control over their data makes a difference
- Efforts are often focused on harnessing AI to use on collections, but the understanding of AI across the whole institution or research community is patchy
- It’s likely that chat-based interfaces will change how new generations are familiar with finding information, so we need to be prepared
Navigation for this conference blog post:
- Behind-the-Scenes Tour of a National Film and Sound Archive (NFSA) Off-site Location
- Behind-the-Scenes Tour of the National Library of Australia
- Against AI Narratives Workshop
- aaDH Algorithmic Humanities panel
- Fantastic Futures Conference Day 1
- Fantastic Futures Conference Day 2
Pre-Conference Events
Behind-the-Scenes Tour of a National Film and Sound Archive (NFSA) Off-site Location
The tour of one of the National Film and Sound Archive (NFSA)’s off-site locations in the suburb of Mitchell enabled a small group of us conference goers to see what goes on behind the scenes in the work of archivists. We saw the racks of various kinds of materials waiting to be reviewed and archived, some of them quite bulky or fragile, and heard about the challenges of the range of items they are tasked with preserving and making accessible. I was thinking of film and sound due to the name, but there are lots of peripheral materials such as papers, costumes, awards, and movie set props that they also care for. We heard directly from archivists on their current projects, such as a costume from Crocodile Dundee, a custom box being made for a beautiful dragon-shaped award, and an organization of film reels from decades ago donated by one collector.


The rows of disks and older media reminded us that things take up physical space and require proper heating/cooling and humidity to remain stable. This tour really opened my eyes to the varied kinds of work that archivists do, and I’d like for more people to understand the efforts involved in preserving cultural heritage items. If you want to keep/preserve something, there’s a cost in terms of time, energy, staffing, and space!


Behind-the-Scenes Tour of the National Library of Australia
The tour of the National Library of Australia offered a glimpse at the work to digitize and photograph important items using high-quality professional equipment. Whereas your average person is limited to taking photos with their smartphone and trying to avoid glare, staff there are able to use big machines designed for this purpose. It was interesting to see the different types of material and also the big photography studio where they can capture very large items like posters as well as small items like manuscripts that can’t be put in the other scanning equipment. They have been exploring how AI can fit into their workflows and speed up activities like transcription.



Against AI Narratives Workshop
Led by Rasa Bočytė (Netherlands Institute for Sound & Vision) and Basil Dewhurst (National Film and Sound Archive), the Against AI Narratives workshop gave us the opportunity to work in small groups to creatively reimagine an AI narrative that differs from the ones perpetuated by Silicon Valley and (stereotypical) science fiction. First, there was some introductory contextual material and an activity to see where we would place ourselves in terms of knowledge about AI and how much we contribute to perpetuating those narratives ourselves. We looked at how the media’s constant talk about the revolutionary and transformational use of AI doesn’t align with what everyday workers in the cultural heritage space are using it for (e.g. transcription, subtitles). This more incremental work does not match with the robots-taking-over-the-world stories that cause fear and anxiety among the public. After the contextual discussion, we got creative designing different scenarios and imagined what a future with AI might look like based on the interests of the members at each table. I enjoyed the attention to language and elements of creativity and craft that we don’t often spend time on as adults.
A recommended resource was Better Images of AI which offers Creative Commons-licensed images that are different from most stock images about AI, offering more color, collages, and diversity.

Australasian Association of Digital Humanities (aaDH) – Algorithmic Humanities panel
Chair: Dr Tyne Daile Sumner (ARC DECRA Fellow, English & Digital Humanities, Australian National University)
Panelists:
- Professor James Smithies (Director, HASS Digital Research Hub, Australian National University)
- Associate Professor Tully Barnett (Creative Industries, College of Humanities, Arts & Social Sciences, Flinders University)
- Professor Mitchell Whitelaw (Head of School of Art and Design, Australian National University)
- Dr Jessica (Jess) Herrington (Futures Specialist, Neuroscientist & Artist, School of Cybernetics, Australian National University)
- Junran Lei (Senior Research Software Engineer, HASS Digital Research Hub, Australian National University)

Having been to Australasian Association of Digital Humanities (aaDH) conferences and events while completing my PhD, I was interested in hearing what people in the Digital Humanities (DH) corner of academia thought about Generative AI and its impact on higher education and research.
James Smithies said he was the most optimistic about DH in 20 years, and has chosen to be positive about the opportunity it represents for the humanities. He discussed how AI-enabled coding, including low- and no-code tools, can lower the barriers to people doing technical stuff and using computational methods. But he said we need to look at how we evaluate these tools and need other tools to look at things like hallucinations and OCR errors. We need to look for tools tailored to research and see if things can be done at scale. People need to be able to determine aspects such as environment costs and how to make decisions (e.g. maybe use a local AI model, or none at all), or which tool to use if concerned with scientific reproducibility. Evaluation frameworks are needed going forward.
Tully Barnett discussed the creative practitioner angle and how people see AI and cultural data very differently based on whether they’re an artist/practitioner or someone from a tech or business sector. She gave an example of someone buying a piece of art and feeling free to replicate it using an AI image generator and discuss this activity in a room full of artists, seemingly with no understanding of why this might be problematic for that audience. The situation might be different if artists were paid decently, but since on the whole they’re not, there’s a power imbalance regarding companies wanting to train on their data. She said we need Critical DH to engage in this space.
Mitchell Whitelaw brought a critical perspective about AI and its averageness. He cautioned that there’s a scholarly history of reading code as text we shouldn’t overlook in this moment, and that there are other algorithms beyond machine learning. He said that average is not what he wants in his cultural life, that cultural production should be pushing on the margins, while AI image generators statistically push toward the middle. He noted that artists have been useful to have around people in industry as a source of inspiration for a long time and that society needs weird tech art to keep being made. He noted there’s a risk that everyone is looking at AI and may be missing other stuff going on. He also mentioned low carbon scholarship and that this needs to address travel in addition to LLMs and technologies that scholars use.
Jess Herrington talked about her work with AI making open-ended games for children undergoing treatments in Sydney hospital, and looking forward to more transparent AI beyond a box that looks like a search box and text.
Junran Lei discussed her work doing OCR improvement on Early Modern texts and that AI tools have both pros and cons that need to be considered.
Tyne Daile Sumner recommended some relevant reading, including AI + University as a Service by Matthew Kirschenbaum and Rita Raley, and the Modern Language Association (MLA)’s work at the intersection of AI and writing.
Fantastic Futures Conference Day 1
The conference began with a Welcome to Country by Aunty Violet Sheridan and a welcome from the host institution, the National Film and Sound Archive (NFSA) of Australia by CEO Patrick McIntyre.
Peter Lucas-Jones and Kathy Reid, in conversation with host Keir Winesmith – Language, Culture and the Machines
Kathy Reid (Australian National University School of Cybernetics) discussed how data is not evenly distributed (riffing off the science fiction writer William Gibson’s quote). Drawing from her research on datasets and performance of AI systems, she said the Common Voice dataset from Mozilla has a bias toward younger people (under 50) and male speakers. Whisper doesn’t work well with accented speech, especially Scottish.
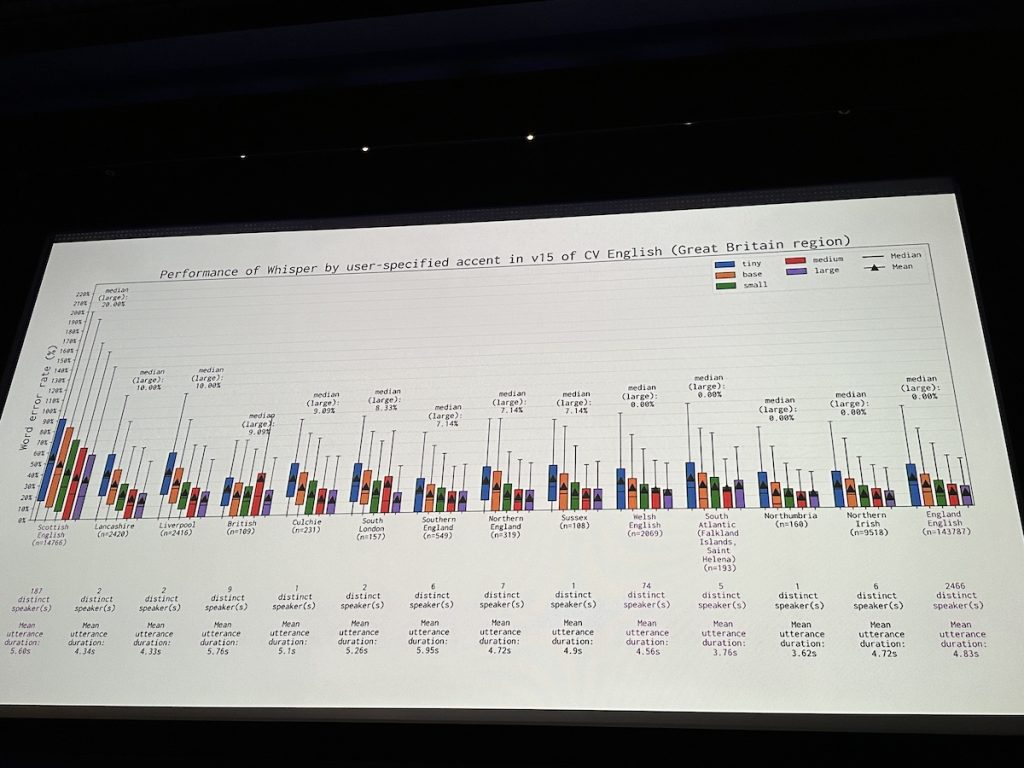
There’s only a small paragraph in a paper about the AI transcription software Whisper about using video transcripts from the internet (unnamed but obviously YouTube), indicating a lack of transparency about AI models. She asked, Did you know your video transcripts would be used for OpenAI’s models and be baked into future products and that they would be essentially selling them via Whisper as a service?
Reid made the point that cultural institutions need to consider what position they take when Big Tech comes knocking for their data. If they have a lot of rich data but also funding issues, this puts them in a position where Big Tech could make them an attractive offer. She also noted that cultural institutions are actors in the “token” economy of AI, and we need to be asking: Who does that data belong to? Institutions are custodians/guardians of data. She’d like to see a national Australian AI model created with multiple stakeholders and Indigenous viewpoints, like an Australian GPT and Australian Whisper. This would mean having Australian AI infrastructure.
Peter Lucas-Jones (Te Hiku Media) discussed some of the concerns with digitization and language translators. One concern his community had with the digitization of their cassettes of the Māori language is that they knew the data would then be stored in the cloud, taking resources on another Indigenous people’s land. He pointed to the FLORES-101 paper which doesn’t address where the data comes from, and said there’s a problem when benchmarking for language translation accuracy is occurring outside the people who speak the language. He said that when Lionbridge offered $45 USD for people to speak their language for training, that was an impetus to do it themselves, and he has built on these efforts with the Māori language in his company, Te Hiku Media. In Papa Reo, their AI model, the error rate is much lower than Whisper and Meta’s. He also noted that a Pacific languages type of LLM is not out of sight.
Keir Winesmith (National Film and Sound Archive) noted that Americans and Europeans might not realize that kids in Australasia are talking to their devices in American accents because they work better.
Grant Heinrich – The First 140 Days: How We’re Teaching Whisper (An American Transcription Engine) To Speak Australian
Grant Heinrich (National Film and Sound Archive of Australia) explained how they wanted to move toward a conversational archive. Their Bowerbird engine is ready and can do in 50 days a transcription of about 20 linear years of audio and can do in 18 months the rest of material that is less accessible. They wanted to try to improve the engine’s Australian, so they put Australian slang into LLMs to make paragraphs (to provide context), then had 40 speakers read the scripts and transcribed those. Unfortunately the model was not better with Australian after all that.
Heinrich also discussed the importance of the three principles NFSA is using to guide their AI usage: build effectively and transparently, create public value, and maintain trust.

Hinana Love – Join Us On A Journey To The Future
Hinana Love (Ngā Taonga Sound & Vision) gave an overview of the archive and the importance of working for communities.
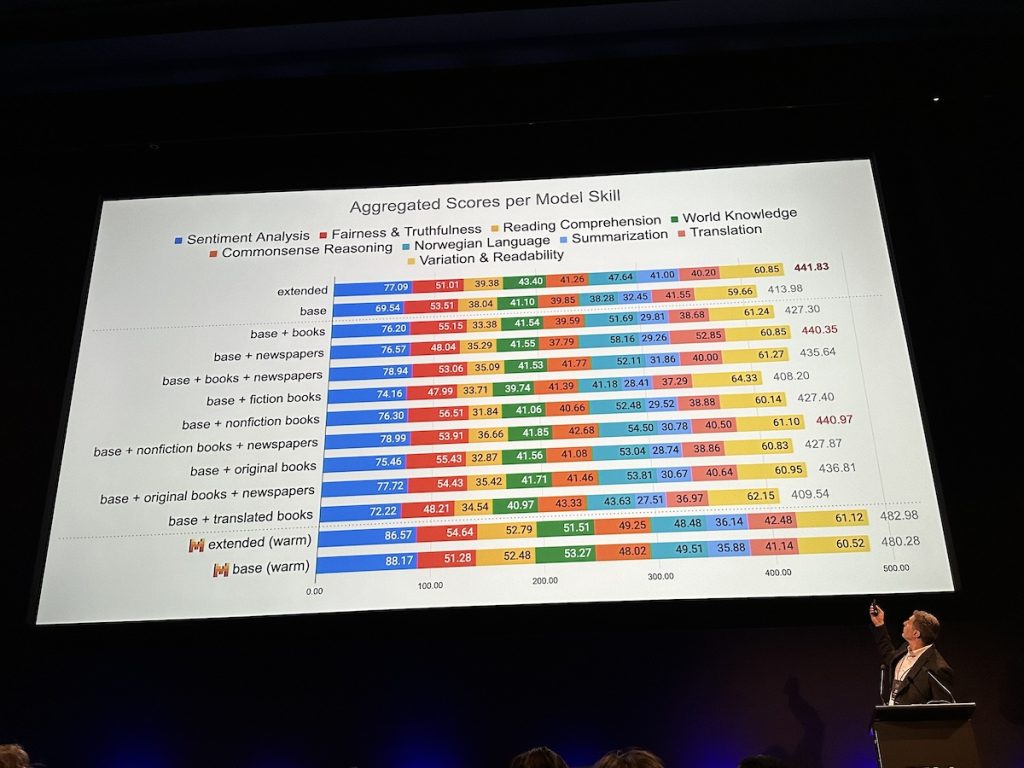
Javier De La Rosa – The Mímir Project: Evaluating The Impact Of Copyrighted Materials On Generative Large Language Models For Norwegian Languages
Javier de la Rosa (National Library of Norway) discussed a project initiated by the Norwegian Ministry of Culture, which wanted researchers to examine the value of copyright-protected material in training Norwegian LLMs (outside the scope for the project is looking at compensation for this material). They didn’t have benchmarks for Norwegian so had to make from scratch. They got around 60 students to help prepare for evaluation and compensated them well with $100k funding. They had to digest the results to make them accessible for political purposes so provided aggregate scores in more readable graphs. They found that the fiction dataset performed the worst, which they believe is because AI tools prioritize factuality not creativity. They believe they need to look at other ways to evaluate performance.
Peter Leonard and Lindsay King – Beyond ChatGPT: Transformers Models for Collections
Peter Leonard (Stanford University Library) and Lindsay King (Stanford University Library) used four transformer models to investigate how to go beyond keywords to look for emotions and feelings in something called evocative search. The transformer models used were: topic modeling with BERTopic, text-to-image networks with CLIP, conversations with an archive, and multi-modal conversations with Florence-2, LLaVa, and mPLUG-Owl. The two caveats were: 1. Language models are not knowledge models; 2. LLMs know the shape of the probable answer.
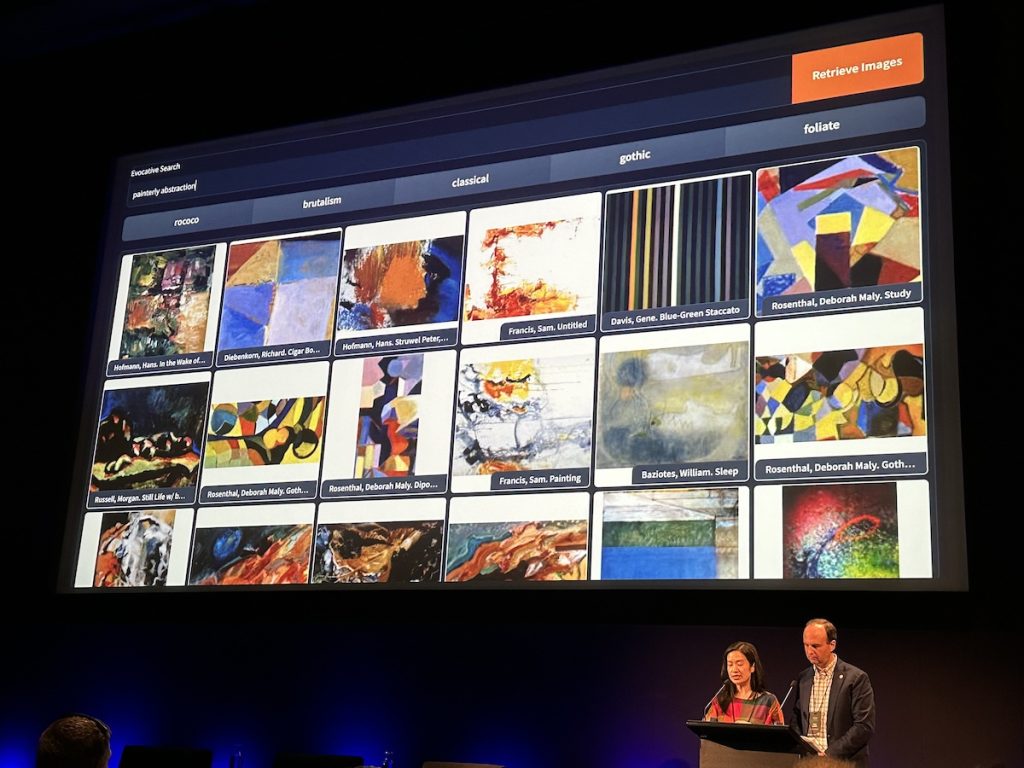
RAG how-to models and options include the ability to build a “ChatGPT” for the 1990s. They created one based on a 1987-1997 archive of documents and showed examples of asking it what would happen between Apple and Microsoft, and it was interesting to see what it predicted based on that knowledge cut-off date.

They emphasized that AI doesn’t have to be a world-class film scholar or art historian to generate useful embeddings. They also noted that although we might not use chat-based interfaces, new students coming to Stanford will.
Mia Ridge – Closing The Loop: Integrating Enriched Metadata Into Collections Platforms
Mia Ridge (British Library) discussed the topic of metadata, including factors for successfully ingesting data from crowdsourcing projects which can involve agreement and collaboration between departments/organizations/teams, discussion of data reuse and standards, distribution of work between teams, and infrastructure that responds to needs. Ridge is Principal Investigator for the Collective Wisdom Project which is documenting crowdsourcing activities and looking to the future of digitally-enabled participation.
Joshua Ng – Archives In The Cloud: Exploring Machine Learning To Transform Archives New Zealand’s Digital Services For Agencies
Joshua Ng (Archives New Zealand) reviewed a project to see if ML could help sort the huge volume of information from New Zealand government agencies according to the regulations around what should be disposed or kept. They got between 75% and 87% accuracy with Microsoft and AWS partners. He noted that there is a need to rewrite the disposal authorities (legal instruments regarding formal authorization for disposal of information and records) to ensure they are fit for purpose in a digital era and that appropriate ontologies are in place. They also need to be in line with the Algorithm Charter for New Zealand.
Peter Broadwell (Absent) – Applying Advances in Person Detection and Action Recognition AI to Enhance Indexing and Discovery of Video Cultural Heritage Collections
Peter Leonard (Stanford University Library) presented on behalf of Peter Broadwell about using Machine Intelligence for Motion Exegesis (MIME), or pose estimation technologies, to study recorded performances in new ways. Newer tech makes it possible to account for when people move behind each other or obstacles on stage and let them still be counted as the same person/instance.

Roxanne Missingham, Kirsten Thorpe, and Sydney Shep – Research, Collaboration and Community
Roxanne Missingham (ANU School of Science), Kirsten Thorpe (University of Technology Sydney), and Sydney Shep (Victoria University of Wellington) discussed issues relating to research and Indigenous communities. Websites and resources mentioned included iREAL (Inclusive Requirements Elicitation for AI in Libraries to Support Respectful Management of Indigenous Knowledges), Te Mana Raraunga: Māori Data Sovereignty Network, Māori Data Governance Model, and Kimihia te Matangaro – a discovery tool for Māori to find land plots and genealogies through publicly accessible data. The issue of a continuing lack of diversity in the makeup of the GLAM (Galleries, Libraries, Art Galleries, and Museums) workforce was raised as something leaders need to keep working on. A distinction was made between decolonization (something for institutions to do) and Indigenizing (something for Indigenous staff to do).
Janet McDougall – Mapping Indigeneity in Institutional Repositories
Janet McDougall (Australian National University) discussed a project to find Indigenous research and connections in repositories.
Benjamin Lee, Kath Bode, and Andrew Dean – Reanimating and Reinterpreting the Archive with AI: Unifying Scholarship and Practice
Benjamin Lee (University of Washington) and Andrew Dean (Deakin University) explained how J.M. Coetzee was first an IBM computer programmer before he became a Nobel Prize-winning novelist. He was working on computational poetry in the 1960s and 70s, long before Generative AI. They are now reanimating his code base and allowing for the ability to make new poems in his style.

Kath Bode (Australian National University) discussed a project to study Irishness in Australian literature and how Claude 3.5 was the best for OCR correction. Bode noted that bad OCR can act like jailbreaking and regurgitate the prompt, and some LLMs might be worse if OCR is bad.

James Smithies and Karaitiana Taiuru – Large Language Models and Transnational Research: Introducing the AI as Infrastructure (AIINFRA) Project
The question emerging for James Smithies (Australian National University) and Karaitiana Taiuru (Taiuru & Associates) is: How should researchers and the GLAM sector judge AI tools? [Smithies discussed this at the pre-conference aaDH session too.] They are at the start of a project to examine this and are hoping to produce a draft framework to aid in this endeavor.

Beth Shulman, Charlotte Bradley, and Ripley Rubens – Imaginative Restoration
Beth Shulman (National Institute of Dramatic Art), Charlotte Bradley (Australian National University), and Ripley Rubens (National Film and Sound Archive of Australia) provided an overview of a project called Imaginative Restorations. They did a 3-day workshop demystifying AI and looking at creative and ethical uses. They have created ML that lets you draw something and have a prompt turn it into something new, like a butterfly across archival videos.
Fantastic Futures Conference Day 2
Kartini Ludwig, Eryk Salvaggio, and Meagan Loader – Creativity, Artists and Generative AI
Kartini Ludwig (Kopi Su), Eryk Salvaggio (metaLAB at Harvard), and Meagan Loader (National Film and Sound Archive) discussed the topic of art and Generative AI with examples of different uses of the technology to create new art and music.
The Think Digital tool available through Creative Australia was mentioned as a way for arts organizations to figure out their digital capability.
An AI-assisted video artwork titled Because of You was about Henrietta Lacks and referenced how data is taken without our consent, just like her cells were taken. The voice-over was done by Avijit Ghosh at Hugging Face, but in the AI process it took out his accent and turned it into a North American accent.
It was mentioned that AI is infrastructure, including training data, GPUs, water, power, and datasets. Something is lost when memories are ‘stored’ in an archive, and it’s important to not diminish the human(s) they go with in the process of making it conform to a computer’s memory.
One way of thinking about an AI prompt is that it is like a seance: you’re conjuring up stuff that may have been forgotten. The example given was of using the prompt “stereoview” in Midjourney. This brings to life generated images based on a training dataset of the colonization of the Philippines in the early 1900s, due to the data from the Library of Congress showing this period of history. Essentially, the context and nuance from the archive are dissolved into noise via the AI dataset and AI tool. It can now be thought of as a Digital Humanities project in reverse because all labels and categories now are prompts. It was hoped that despite the problematic nature of some of this usage, that this wouldn’t be an excuse for institutions to close down their collections out of fear.
Another example was an AI music generator prototype based on Riffusion for artists to make AI music. The new tool called Koup had its name inspired by Catherine the Great.
The idea was proposed that the more metaphors we have for AI, the better, and artists can be part of offering different metaphors. We don’t have to accept Silicon Valley’s explanations of AI or how it learns. We should consider that any time we put an image up on social media or a website, we’re building a dataset with unpaid labor. But there are people building alternatives to this, to allow artists to package their datasets and sell them to anyone who wants to train on it.
Emmanuelle Bermès – Computer Vision In The Museum: Perspectives At The Mad Paris
Emmanuelle Bermès (Ecole nationals des chartes / PSL) discussed museum collections and CLIP, and some of the challenges of incorporating AI and automation into the museum context.

Jeff Williams – AI Ambassadors: How to Demystify AI and Encourage Experimentation
Jeff Williams (Australian Centre for the Moving Image – ACMI) discussed how to bring your staff on the AI journey and offered an insightful view of how ACMI was upskilling staff on AI through a range of professional development opportunities. He reiterated that you can’t rely solely on technologists to help you understand this tech. Initially, ACMI started with formal presentations on AI, but then shifted to more focused discussions that were more engaging and didn’t give homework anymore. Diverse, non-technical terms are crucial to include, and they revisit key topics frequently because AI and opinions are changing fast. They have lunch and learn sessions 4 times a year, with dozens of attendees. They try to have a 50/50 balance of presentation and discussion time and keep explanations clear and concise.


Jon Dunn – Whisper Applied to Digitized Historical Audiovisual Materials
Jon Dunn (Indiana University Library) looked at the Whisper technology being applied to audiovisual materials from the library.
Emily Pugh – AI-Generated Metadata and the Culture of Image Search
Emily Pugh (Getty Research Institute) reviewed a survey of people in the US about their contemporary image search practices, targeting scholars in art and art history. They found that art historians are open to using computer-generated metadata, but that a lot of people were unfamiliar with approaches like computer vision, crowdsourcing, and OCR.
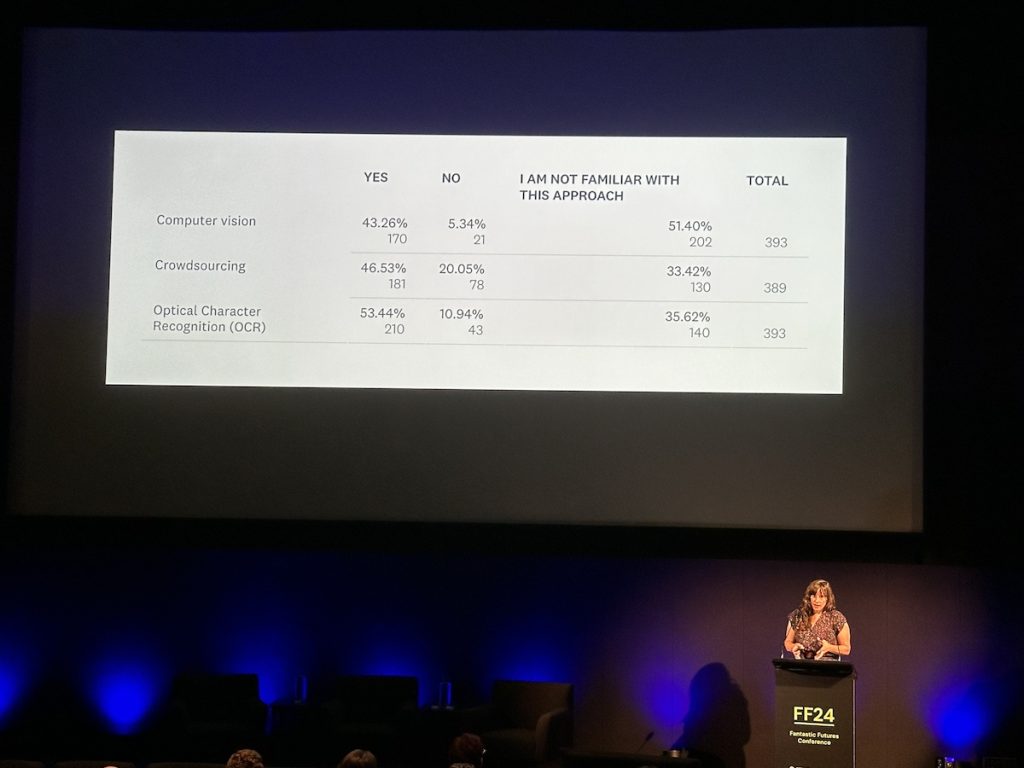
They found that data provenance is increasingly important to people, and believe they need to communicate to users what they’re looking at in image databases and how these searches relate to Google search, which is what people are most familiar with.
Kirsten Thorpe, Lauren Booker, and Robin Wright – Responsibility for the Care and Protection of Indigenous Knowledge
Kirsten Thorpe (University of Technology Sydney), Lauren Booker (University of Technology Sydney), and Robin Wright (Digital Preservation Coalition) talked about the topic of Indigenous knowledge and how to protect it. They mentioned the Indigenous Archives Collective, which connects people working with Indigenous knowledge in GLAM sector, and the Maiam nayri Wingara Indigenous Data Sovereignty Collective, which has information and resources on the topic of Indigenous data sovereignty. The need to discuss and communicate with members of Indigenous communities, even in a relatively short 6-month project, was emphasized.
Morgan Strong – Converging AI to Access Digital Content in Art Museums
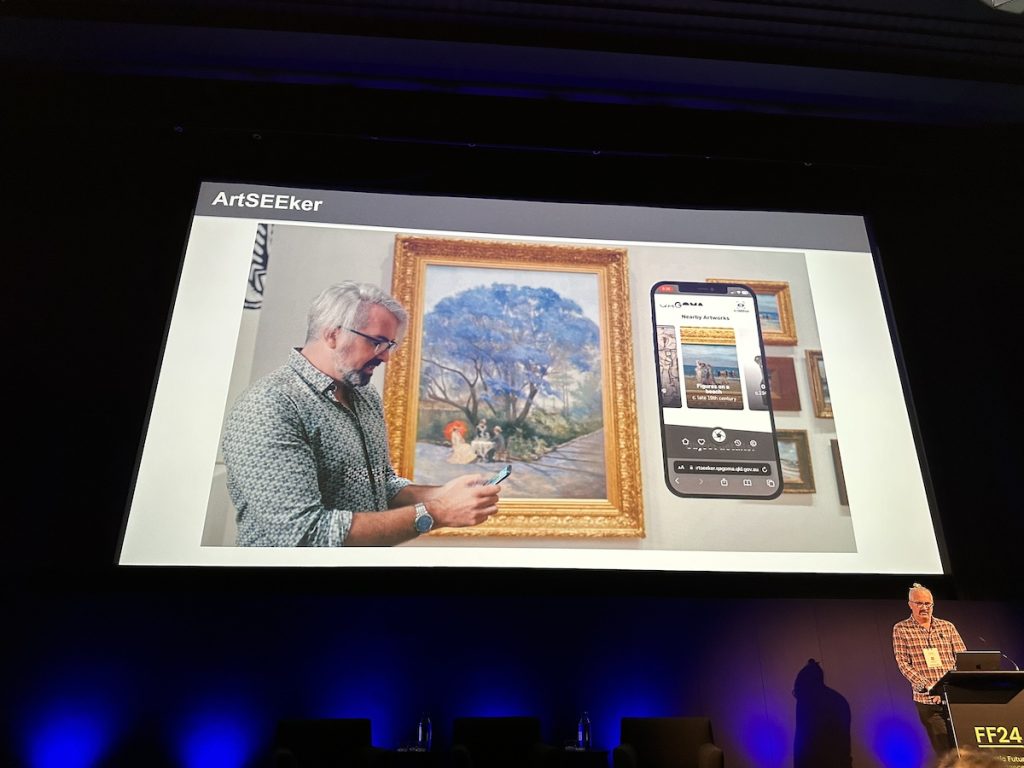
Morgan Strong (Queensland Art Gallery / Gallery of Modern Art) discussed the start of a digital transformation project in 2020 and showed one of the results of this, the ArtSEEker app. With this app, you can take a photo of an artwork in their gallery and it shows a range of information on your device, including the color palette used by the artist, other artworks in their collection with the same color palette, and links to any blog posts about the artwork. There’s also a short survey about how you feel about the artwork and the ability to leave a comment. Their intention is to lower the barrier to visitors who may not know art well. They are also using it in partnership with an Audit app that is helping reduce staff time monitoring the collection. Strong noted that it was nice to be able to use the Fast.ai deep learning library since it’s a Queensland-based project.
Miguel Escobar Varela – AI-Assisted Analysis of Malay-Language Periodicals in Singapore
Miguel Escobar Varela (National University Singapore) discussed a project to digitize 80,000 newspaper pages and how AI was assisting with the complications of the language, which previously used a modified Arabic script named Jawi and had English advertisements as well. He and colleagues made flash cards for learning Jawi and found that the QWEN2 model from Alibaba was much better (~91% accuracy) than other tools. More information is available on his Hugging Face page.
Katrina Short and Marni Williams – Preparing Research Practices and Publishing Infrastructure for the AI-Era
Katrina Short (University of Sydney Power Institute) and Marni Williams (University of Sydney Power Institute) looked at changes happening in the publishing world in light of AI. They discussed how there remains a tendency to publish in traditional places like books or paywalled places. Meanwhile, art often appears frequently in pop websites like Pinterest but doesn’t always contain the rich data and context that it could. They noted that context and other information is often flattened when turned into pixels, but they are exploring new ways to present cultural data and contextual information outside of static books. They are now making data and annotations along the way and reinstating materiality, rather than waiting until the end to publish a book/monograph with 1 ISBN that can’t be changed. They discussed the hope of building up a dataset over time. This represents a shift toward something new beyond the individual author and academic publishing model. They mentioned Womanifesto, a global art collective.
Neil Fitzgerald – Digitisation Was Only the Start
Neil Fitzgerald (British Library) provided an overview of what’s been happening at the British Library in terms of their digital projects. He said digitization was only the start and included several links to projects and tools being used, including the IMPACT Dataset, Towards a Books Data Commons for AI Training, Transkribus (OCR, recognition of handwritten and printed text), and Escriptorium.
Francis Crimmins – Evaluation of Techniques that Improve Findability of Historic Images in a Large and Diverse Corpus Using AI Vision Models and Embeddings
Francis Crimmins (National Library of Australia) showed a project to use AI on their system to allow for users to be able to surface other images even when keywords aren’t in the metadata. Examples included the phrases “2 birds on a branch”, “art deco”, and “dark and moody lighting”. He discussed open-source models as a viable alternative to proprietary AI models.

Lightning Talks
Laura McGuiness – Just One More Access Point: LLM Assistance with Authority Control
Laura McGuiness (Los Alamos National Laboratory) looked at issues with metadata and the use of AI, and recommended the book Ethical Questions in Name Authority Control, edited by Jane Sandberg.
Kate Follington – 19th C. Handwriting and “Model Making” with Transkribus
Asa Letourneau (Public Record Office Victoria, State Archives Victoria) presented on behalf of colleague Kate Follington on how they uploaded the entire Ned Kelly Historical Collection (6,712 pages) and transcribed it in 46 hours with an error rate (CER) of under 3%. They want to start a culture of ML in their organization.
Rachel Senese Myers – Adopting Whisper: Creating a Front End Optimized for Processing Needs
Rachel Senese Myers (Georgia State University Library) discussed how they tried Whisper and WebUI for transcription but are now creating their own called Whisper Scribe.
Barbara Shubinski – Gender in a (Supposedly) Non-Gendered Historical Space: Generative AI, Sentiment Analysis, and Graph Databases in the Rockefeller Foundation Collections of the 1930s
Barbara Shubinski (Rockefeller Archive Center) showed how AI was helping in an analysis of grants made in the early 20th century, which looked at sentiments and discrimination against women. One example was that the AI tool surfaced how program officers always put Ms. or Mrs. in front of women’s names, even if they were Dr. or Prof.

Kara Kennedy – AI Literacy for Librarians in Low-Resource, Multicultural Communities
I presented on the topic of AI literacy with three strategies that I’ve been employing in New Zealand among librarians and learning advisors to help increase awareness and understanding around Generative AI: engage an AI champion who knows your local/industry context; leverage existing resources like LinkedIn, Facebook, and virtual webinars and conferences; and create resources that your community can use. I’ve been making Creative Commons-licensed guides that are simple and colorful to ensure they are inclusive enough to be used by students from a range of literacy, English, and digital skill levels.
Karen M. Thompson – Applying AI to Accelerate Transcription
Karen M. Thompson (University of Melbourne) discussed the complexities of herbarium pages, where text can be found anywhere, labels evolve over time, the kind of text differs, and the language changes with Latin for taxonomy and sometimes non-English text as well as English labels. They are calling their AI Hespi (Herb Specimen Pipeline). Computer vision outlines different components of non-plant data on the page, and then the data is run through Claude Sonnet’s LLM. The model and annotations are freely available if others would like to use it for their collections.

The next Fantastic Futures conference will be held in December 2025 in London.

